Виктор Пелевин, «Чапаев и пустота»
— А у вас случайно нет такого знакомого с красным лицом, тремя глазами и ожерельем из черепов? — спросил он. — Который между костров танцует? А? Еще высокий такой? И кривыми саблями машет?
— Может быть и есть, — сказал он вежливо, — не могу понять о ком именно вы говорите. Знаете, очень общие черты. Кто угодно может оказаться.
Привет, Хабр! Меня зовут Александр Соловьев, я руковожу технической поддержкой в дата-центре Миран.
Некоторое время назад я принимал участие в интересном митапе, посвященном KPI технической поддержки. В целом это было полезное мероприятие с точки зрения обмена опытом. Но все же, остался осадок некоторой “незавершенности”. Причина прежде всего в том, что участники мероприятия делились своим опытом, а какого-то обобщения или даже итогов ни они ни я не подвели.
Мероприятие было организовано сообществом специалистов техподдержки “SUPNET” которое, судя по последней публикации на их официальной страничке, от сентября 2018, “ушло в нирвану”.
Поэтому я взял на себя смелость в этой статье поделится своим наработками и попробовать обобщить сказанное тогда на основе своего опыта.
Так вот, если рассматривать нашу техническую поддержку как “черный ящик”, то можно сказать так: этот ящик выполняет полезную функцию, трансформируя неформализованные обращения за поддержкой в формализованные выполненные заявки. Ящик обладает определенной производительностью, выполненные заявки соответствуют заданному уровню качества, а эксплуатация ящика обходится у нас довольно дорого.
В целом, это все, что знать нужно про KPI технической поддержки, однако если интересны подробности — добро пожаловать под кат… Туда же приглашаются все кому я обещал рассказать про индекс уровня знаний.
Итак, KPI у нас делятся на три группы:
- Показатели эффективности — отражают эффективность затрат на достижение определенного результата, например, средняя зарплата инженера.
- Показатели результативности — фактически “прогресс-бар”, например, процент нарушений времени реакции на заявку за отчетный период.
- Производственные показатели — значимые показатели оперативной деятельности, например, количество обращений в техническую поддержку за отчетный период.
Показатели эффективности
Начну с эффективности.
- Cредняя зарплата инженера техподдержки;
- FRT — среднее время первого отклика на заявку;
- ART — среднее время выполнения заявки;
- MTTR — среднее время ремонта.
Средняя зарплата инженера
Поскольку заработная плата у нас сдельная, смысл этого индикатора — показать менеджменту, на каком свете, по выражению нашего генерала, находится ФОТ инженеров технической поддержки. После ввода в эксплуатацию “балансировки” ФОТ через нефинансовую мотивацию актуальности у индикатора поубавилось, но в целом он считается и поныне. Добавлю, что значение индикатора рассчитывается для каждой линии технической поддержки, что позволяет уже мне держать руку на пульсе и при необходимости корректировать тарифы сдельной оплаты труда на следующий месяц.
FRT / ART
Оба показателя “растут” из SLA (Service Level Agreement). Следуя SLA, при превышении FRT / ART у клиента появляется право на перерасчет размера оплаты услуг подвергшихся деградации. На мой взгляд, эти индексы по смыслу похожи на среднюю температуру по больнице). В практическом плане пользы от индексов не много, единственное что они позволяет менеджменту компании понять что заявленные в SLA показатели примерно выполняются. Гораздо полезнее процент нарушений времени реакции / выполнения заявки, эти индикаторы позволяют быстро и наглядно оценить динамику обработки заявок технической поддержкой.
MTTR
Широко известный в узких кругах индикатор (он же, IRT — incident Resolution Time), среднее время ремонта, в нашем случае польза от индикатора невелика поскольку предоставляемые нашей компанией услуги по характеру очень разнятся. Может в дальнейшем будем считать MTTR отдельно для каждого продукта. Однако, поскольку это действительно известный индикатор мы его считаем.
Показатели результативности
Перейдем к результативности.
- EKi — индекс уровня знаний сотрудника;
- CSi — индекс удовлетворенности клиента обслуживанием;
- FRTR — процент нарушения времени реакции на обращение;
- ARTR — процент нарушения времени выполнения заявок.
CSi
Индекс удовлетворенности клиента обслуживанием — это оцифрованная обратная связь от потребителя, т.е. мнение клиента о качестве полученных услуг. Расчета индекса производится исключительно на основании субъективных оценок клиента которые мы получаем после выполнения каждой заявки. CSi важнейший индикатор, самый понятный и заходящий абсолютно всем. В отличии от предыдущих индикаторов, методика расчета коих очевидна, подробно расскажу о нашей методике расчета CSi.
Значение индекса зависит от трех параметров:
- Время реакции на обращение, t1;
- Время решения заявки, t2;
- Качество решения заявки, q.
Формула для расчета CSi следующая:
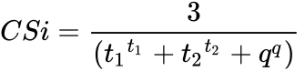
Диапазон возможных значений параметров приведен в таблице
| Параметры | Значения |
|---|---|
| t1 | 1 — быстро; 2 — удовлетворительно; 3 — медленно; |
| t2 | 1 — быстро; 2 — удовлетворительно; 3 — медленно; |
| q | 1 — хорошо; 2 — удовлетворительно; 3 — плохо; |
Полученные значения интерпретируются согласно следующей таблицы
| Значение CSi | Вывод |
|---|---|
| CSi = 1,0 | Клиент полностью удовлетворен обслуживанием |
| 0,25 ≤ CSi < 1,0 | Обслуживание находится на приемлемом для клиента уровне |
| CSi < 0,25 | Клиент не доволен обслуживанием |
EKi
Индекс уровня знаний сотрудника показывает соответствие знаний сотрудников минимально допустимому уровню приемлемому для инженера технической поддержки. Позволяет пресечь порожние разговоры о некомплектности инженеров показать менеджменту компании насколько компетентны и готовы к работе инженеры технической поддержки. Индекс не очень заходит инженерам, но хорошо заходит менеджменту и нашим пиарщикам).
Расчета индекса производится на основании объективных данных полученных в результате регулярной проверки тренировки знаний инженеров, проводимой по методике имитационного моделирования, а именно решения типовых ситуаций называемых юзкейсами. Кому интересно, подробнее про управление знаниями в техподдержке рассказывал на KnowledgeConf 2019.
В нашей компании EKi рассчитывается как отношение успешно выполненных юзкейсов к общему количеству юзкейсов за период.
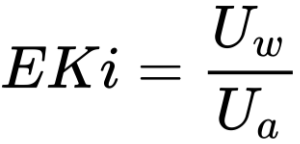
где,
Uw — количество успешно решенных инженером юзкейсов за отчетный период;
Ua — общее количество решенных инженером юзкейсов за отчетный период.
Полученные значения интерпретируются согласно следующей таблицы
| Значение EKi | Вывод |
|---|---|
| EKi > 0,95 | Знания инженера более чем адекватны занимаемой позиции |
| 0,85 ≤ EKi ≤ 0,95 | Знания инженера находятся на приемлемом уровне |
| EKi < 0,85 | Знания инженера не достаточны |
Уровни 0,85 и 0,95 получены нами экспериментально экспертно, в результате более чем двухлетней практики управления знаниями инженеров технической поддержки.
Процент нарушения времени реакции / времени выполнения
Индексы процент нарушения времени реакции / времени выполнения я упоминал выше. По сути показывают насколько часто техподдержка нарушает SLA в части времени реакции и времени выполнения заявок.
Производственные показатели
Ну напоследок, производственные показатели:
- количество обработанных технической поддержкой заявок за отчетный период:
- из них звонков;
- из них сообщения от системы мониторинга;
- из них отклонено;
- из них клиентские;
- количество заявок связанных с эксплуатацией продукта в отчетном периоде:
- из них инцидентов;
- из них обращений;
- суммарное время “отказа в обслуживании” для всех клиентов по продукту за отчетный период.
Есть правило определяющее соотношение KPI для оценки эффективности работы в целом. Согласно этого правила индикаторы должны распределятся в пропорции 10/80/10 = показатели эффективности / производственные показатели / показатели результативности.
По этой причине производственных показателей много и я остановлюсь только на самых важных с моей точки зрения.
Количество обращений в техническую поддержку
Понятное дело количество обращений в техническую поддержку важный показатель который необходимо учитывать и для организации работы и для отражения производительности техподдержки. Заходит всем)
Поскольку обращения обращениям рознь, разумно дифференцировать общий поток обращений по совокупности источников обращений и “сущности” обращений. В нашем случае это системы мониторинга, входящие вызовы по телефону, ошибочные обращения и наконец клиентские обращения.
Количество заявок связанных с эксплуатацией продукта
С другой стороны имеет смысл интегрировать обращения касающиеся каждого из наших продуктов (услуг) в одноименные группы. Например, в нашем случае, целесообразно группировать обращения связанные с услугами аренды вычислительных мощностей и услугами связанными с размещением оборудования в дата-центре в разные группы. Хорошая практика когда внутри группы обращения делятся на общее количество обращений, количество “отказов в обслуживании” и общее время простоя по услугам входящих в продукт.
Заключение
Когда было уже поздно что существенно менять Как обычно, после написания статьи гуглил KPI технической поддержки, нагуглил несколько интересных статей, в вот пара из них:
Осмыслил прочитанное и ничего в своей статье менять не стал, потому что так мне кажется честнее и естественней. При желании, читатель может проверить сам насколько наша техподдержка “в тренде”.
Пожалуй главное что вынес из прочитанного, в нашей техподдержке следует завести два дополнительных индекса:
1. FCR — количество заявок решенных в рамках первого обращения за поддержкой;
2. FTFR — процент заявок решенных в рамках первого обращения за поддержкой.